Python
a = {'name' : '영수', 'age' : 24}
print(a['name'])파이썬에서는 객체, 배열 생성하는 방법과 불러내는 방법이 모두 비슷하다. 다만 파이썬에서는 자바스크립트에서와 같이 let 이나 const로 변수를 선언할 필요 없이 그냥 변수명만 써서 선언 할 수 있다.
def hello():
print('hello world')
hello()
def는 함수를 선언한다는 의미이다. 자바스크립트에서는 함수의 내용을 중괄호로 표현을 했으나 파이썬에서는 콜론으로 표시한다.
또 파이썬에서는 자바스크립트와 다르게 함수명 : 을 한 다음에 다음 줄에서 꼭 탭을 해줘야한다. 그래야 이게 함수의 내용이구나 이해를 한다.
또 자바스크립트와 다르게 console.log(hello()) 와 같이 호출하여 출력을 할 필요 없이 바로 함수를 호출하면 결과물이 출력이 된다.
def sum(a,b,c):
return a+b+c
result = sum(1,2,3)
print(result)매개변수 a,b,c 3개를 받는 sum이라는 함수는 a + b + c 값을 리턴한다. 변수 result에 sum 함수를 호출하여 매개변수에 1,2,3을 넣어줬고 result 값을 출력했다.
let age = 25
function age123(age){
if(age > 20){
return '성인입니다'
}
else{
return '청소년입니다'
}
}
console.log(age123(age))위 코드는 자바스크립트 언어로 짠 코드이고
age = 25
if age > 20:
print('성인입니다')
else :
print('청소년입니다')이 코드는 파이썬으로 짠 코드이다. 차이점을 보면 괄호가 필요가 없고 console.log 없이 실행만 하면 결과물이 출력되는 것을 알 수 있다.
ages = [5,10,13,23,25,9]
for a in ages:
if a > 20:
print('성인입니다')
else:
print('청소년입니다')청소년입니다
청소년입니다
청소년입니다
성인입니다
성인입니다
청소년입니다
let age = [5,10,13,23,25,9]
for(let a of age){
if(a > 20){
console.log('성인입니다')
}
else{
console.log('청소년입니다')
}
}자바스크립트로 짠 똑같은 내용의 코드이다. 차이점을 잘 보자
가상환경 venv
패키지를 담아두는 공구함이라고 생각하면 된다. 가상환경(virtual environment)는 같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해, 파이썬 배포 패키지들을 설치하거나 업그레이드 하는 것을 가능하게 하는 격리된 실행 환경이다.

위와 같이 터미널에서 실행하면 venv 폴더가 생기면서 가상환경이 구현되게 된다.

그 후 오른쪽 하단에 인터프리터를 눌러서 중앙에 위와 같은 창이 뜨는게 venv로 표시된 부분을 클릭한다.

터미널을 닫고 새로운 터미널을 열게 되면 위와 같이 (venv)가 붙어서 나오는 모습을 볼 수 있다. 즉, 이 폴더에서 라이브러리를 가져다가 쓰겠다는 의미이다.

requests 라는 라이브러리(패키지)를 깔겠다는 의미이다. 이 라이브러리는 자바스크립트에서 Fetch 라는 것과 비슷하다.
서버에서 데이터를 가져와서 사용하겠다는 의미이다.
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()requests 라이브러리를 import 하고 아래 코드를 보면 자바스크립트의 Fetch와 비슷한 모습인걸 알 수 있다.
import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
print(rjson)이 코드를 치면 아래와 같이 url에 있는 데이터가 모두 출력된다.

import requests # requests 라이브러리 설치 필요
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for a in rows:
gu_name = a['MSRSTE_NM']
gu_mise = a['IDEX_MVL']
print(gu_name,gu_mise)변수 rows 에 rjson의 row 데이터에 접근해서 할당을 해주고 반복문을 사용해 미세먼지 데이터와 구 이름 데이터를 반복하여 출력해내는 코드이다. 실행하면 아래와 같이 출력된다.
| 중구 31 종로구 39 용산구 -99 은평구 42 서대문구 37 마포구 36 광진구 31 성동구 33 중랑구 34 동대문구 34 성북구 37 도봉구 41 강북구 39 노원구 36 강서구 42 구로구 37 영등포구 41 동작구 41 관악구 37 금천구 43 양천구 -99 강남구 39 서초구 41 송파구 42 강동구 39 |

웹 크롤링

여기서 bs4 는 beautifulsoup4 의 줄임이다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작웹 크롤링을 하려면 서버에 접속해서 데이터를 가져와야 하기때문에 requests 라이브러리가 필요하고 솎아내서 가져오기 위해 beautifulSoup 라이브러리가 필요하다. 위 코드는 웹크롤링을 하기 위한 기본 포멧이다.

위 코드에서 print(soup)를 실행하게 되면 이와 같이 HTML이 출력되게 되고, 우리는 웹크롤링을 하기 위해 원하는 데이터만 솎아내면 된다.

이 페이지에서 그린 북 텍스트 위에 마우스를 대고 오른쪽 클릭한 뒤 검사를 누르면
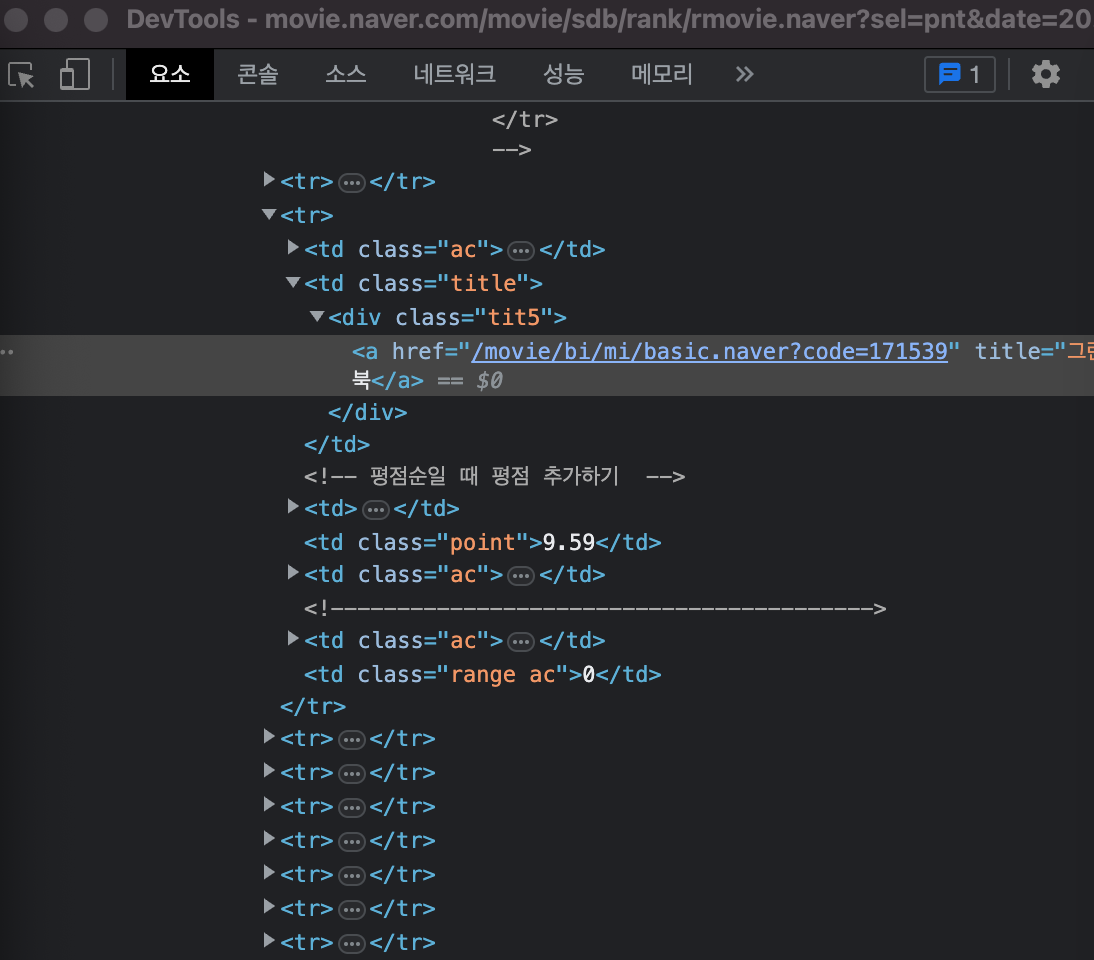
이와 같은 창이 뜨게 되는데 여기서

selector 복사를 한뒤
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
a = soup.select_one('#old_content > table > tbody > tr:nth-child(3) > td.title > div > a')
print(a)select_one(' ') 내에 붙여넣기를 해주고 print를 해주면

이와 같이 해당 내용만 나오게 된다. 여기서 print(a.text)를 해주면 text 데이터만 뽑아와서 그린 북 만 출력되게 된다.
만약 href 값만 가져오고 싶다면 print(a['href']) 을 실행하면 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)
trs = soup.select('')이제 영화의 제목들만 가져오려고 한다.

이렇게 <tr> 내에 영화 제목 데이터가 있음을 알 수 있으므로

이렇게 접은 후에 <tr> 을 copy selector 해서 두개 정도 가져와서 비교해보면 겹치는 부분이 있음을 알 수 있다.
#old_content > table > tbody > tr:nth-child(2)
#old_content > table > tbody > tr:nth-child(3)tr : 까지 공통임을 알 수 있으므로 공통인 부분까지를 select('')내에 넣어주면 변수 trs에 모든 tr 데이터가 할당된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a != None:
print(a.text)모든 tr의 공통 부분을 trs에 할당해주고 반복문을 통해 trs 의 데이터를 tr에 반복하여 넣어준다. 이때 제목 데이터만 필요하므로

제목이 들어있는 부분만 copy select 하여 긁어와준다. 이때 해당 값을 복사해서 그냥 넣어주면 '밥정' 데이터만 출력이 되므로 공통 부분을 select('')에 넣어서 모든 영화 제목 데이터가 반복하여 출력될 수 있도록 한다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > aa = tr.select_one('td.title > div > a') 만 들어가게 되는 이유는 위 코드에서 공통되는 부분은 td.title 부터고 앞부분은 이미 trs에 할당이 되어 있기 때문이다. 이때 None 이 아니라면 a의 text만 출력하라는 조건문을 사용해 영화의 제목만 출력할 수 있다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
rank = tr.select_one('td:nth-child(1) > img')
if a != None:
title = a.text
print(rank['alt'])이젠 순위 데이터를 가져오려고 한다.

순위는 해당 부분에 있으므로 copy select를 해준 뒤 공통 부분만 select_one('')에 넣어주고 변수 rank에 할당시켜준다.

print(rank)를 찍어보면 위와 같이 나오는데, 필요한 데이터는 alt 값이므로 print(rank['alt'])로 찍어주면 순위 숫자만 출력되게 된다.
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a != None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text
print(star)
#old_content > table > tbody > tr:nth-child(2) > td.point
#old_content > table > tbody > tr:nth-child(3) > td.point평점을 가져오려고 한다. 마찬가지로 select_one을 사용해 공통되는 부분인 td.point만 넣어주고 .text를 통해 원하는 데이터만 나오게 한다.
| 9.64 9.59 9.59 9.53 9.52 9.52 9.52 9.51 9.49 9.48 9.48 9.47 |
그럼 이와 같이 출력이 된다.(양이 많아서 뒷부분은 잘랐음)
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a != None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text
print(rank,title,star)최종적으로 위 코드로 실행을 하면
| 01 밥정 9.64 02 그린 북 9.59 03 가버나움 9.59 04 디지몬 어드벤처 라스트 에볼루션 : 인연 9.53 05 원더 9.52 06 베일리 어게인 9.52 07 먼 훗날 우리 9.52 08 아일라 9.51 09 당갈 9.49 010 극장판 바이올렛 에버가든 9.48 11 포드 V 페라리 9.48 12 주전장 9.47 13 쇼생크 탈출 9.45 14 터미네이터 2:오리지널 9.44 15 덕구 9.43 16 나 홀로 집에 9.43 17 라이언 일병 구하기 9.43 18 클래식 9.42 19 잭 스나이더의 저스티스 리그 9.42 20 그대, 고맙소 : 김호중 생애 첫 팬미팅 무비 9.42 21 월-E 9.42 22 보헤미안 랩소디 9.42 23 사운드 오브 뮤직 9.41 24 포레스트 검프 9.41 25 빽 투 더 퓨쳐 9.41 26 위대한 쇼맨 9.41 27 글래디에이터 9.41 28 헬프 9.41 29 인생은 아름다워 9.40 30 타이타닉 9.40 31 매트릭스 9.40 32 살인의 추억 9.40 33 센과 치히로의 행방불명 9.39 34 토이 스토리 3 9.39 35 가나의 혼인잔치: 언약 9.39 36 헌터 킬러 9.39 37 캐스트 어웨이 9.38 38 집으로... 9.38 39 아이즈 온 미 : 더 무비 9.38 40 반지의 제왕: 왕의 귀환 9.38 41 죽은 시인의 사회 9.38 42 히든 피겨스 9.38 43 알라딘 9.38 44 어벤져스: 엔드게임 9.38 45 레옹 9.38 46 쉰들러 리스트 9.37 47 아이 캔 스피크 9.37 48 동주 9.37 49 안녕 베일리 9.37 50 클레멘타인 9.37 |
이와 같은 결과를 얻을 수 있다.
DB
저장해놓은 데이터를 필요할 때 잘 가지고 올 수 있게 하는 것이 DB의 역할이다.
https://account.mongodb.com/account/register
Cloud: MongoDB Cloud
account.mongodb.com
mongoDB 데이터베이스를 사용할거다.

아래 화면에서 Bulid a Database 를 누른 뒤
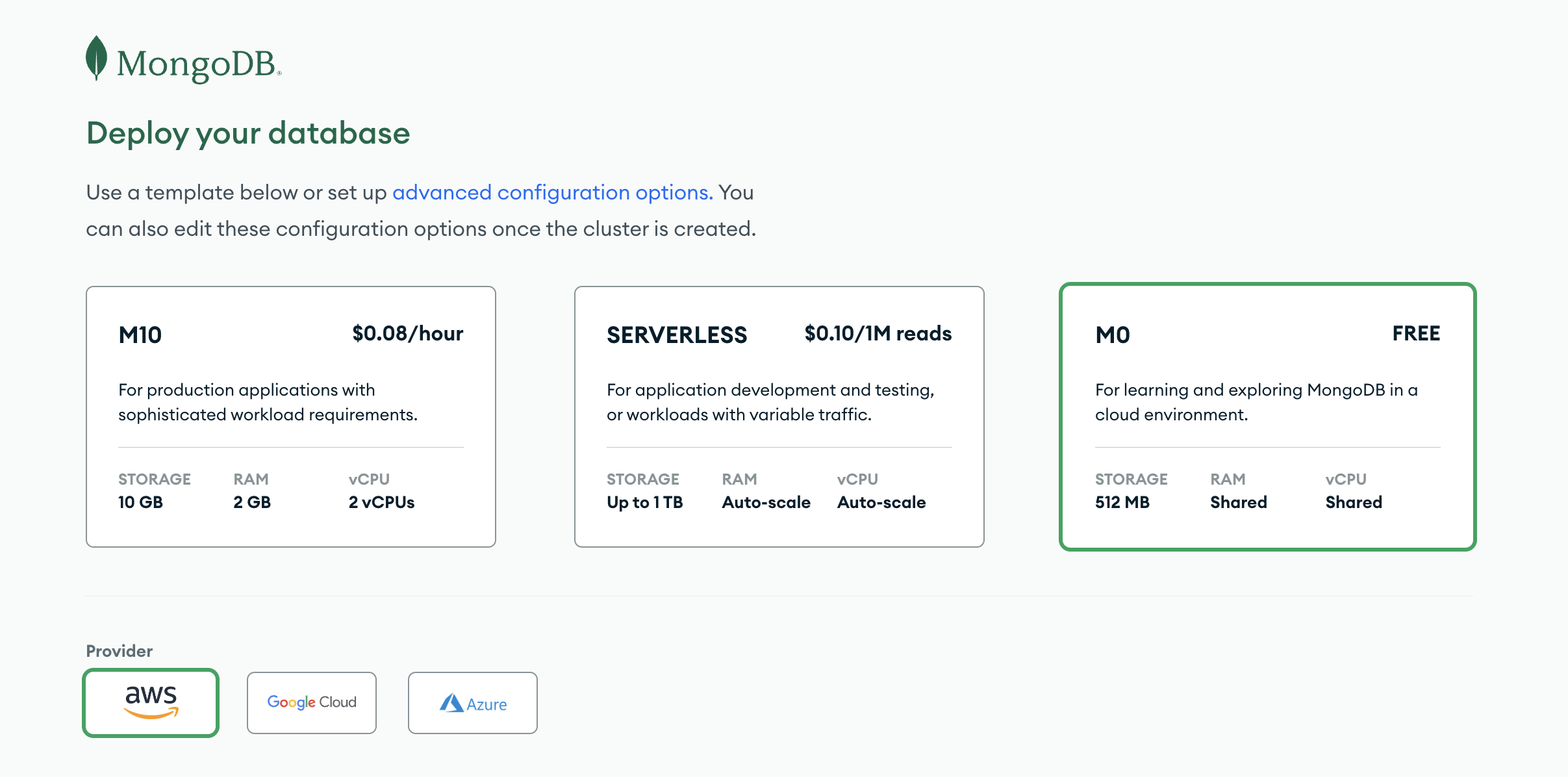
가장 오른쪽에 있는 Free 옵션을 클릭한 뒤 아래에 create 를 눌러준다.

username과 password를 기입한 후

IP Address 에 0.0.0.0 입력 후 Add Entry을 누른다.
여기까지 진행하면 접속 준비가 완료된 것이다.
개설한 mongoDB를 파이썬에서 연결한다. 즉, 내 컴퓨터와 인터넷에 있는 mongeDB를 연결하는 것이다.
mongeDB를 조작하려면 두개의 라이브러리가 필요하다. pymongo 와 dnspython 이다.
from pymongo import MongoClient
client = MongoClient('여기에 URL 입력')
db = client.dbspartapymongo의 기본 코드이다.

connect를 누르고

connect your application을 누른다
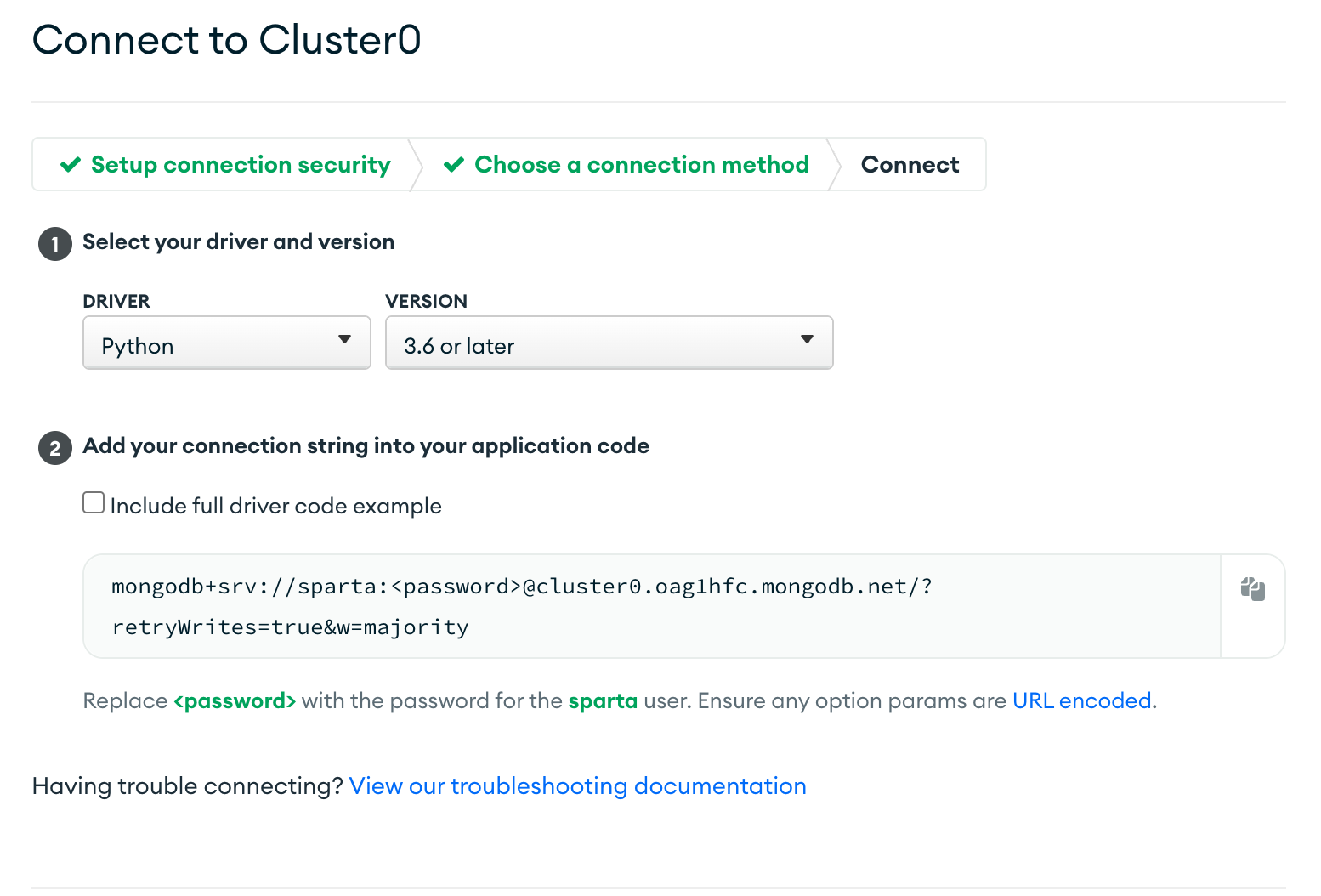
위와 같이 드라이버와 버전을 선택한 후 아래의 url을 복사하여 붙여넣는다
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:<password>@cluster0.oag1hfc.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta<password> 부분을 지우고 아까 패스워드로 설정한 test로 수정한다.
무슨 오류인진 모르겠으나 위 코드와 3.6 버전으로 실행하면 데이터베이스에 데이터가 담기지 않아서 아래 코드로 진행을 했다.
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
doc = {
'name':'bob',
'age':27
}
db.users.insert_one(doc)3.4 or later 버전으로 진행했고 큰틀은 같다. doc 딕셔너리를 db에 넣어주려고 db.users.insert_one(doc) 코드를 실행했다.

실행 후 browse collections 을 눌러 들어가보면

이와 같이 데이터가 저장되어 있는 모습을 볼 수 있다.
Pymonge를 이용해서 mongodb 조작
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
all_users = list(db.users.find({},{'_id':False}))
for a in all_users:
print(a)
all_users = list(db.users.find({},{'_id':False}))위 코드에서 이 코드는 db에서 데이터를 가져오기 위한 코드이다. db의 users 에서 find 하는데 {} 괄호안에 조건이 없는 상태이다.
만약 '_id' : False 를 없애고 print를 해보면
| {'_id': ObjectId('6418428374096d0a17110f66'), 'name': 'bob', 'age': 27} {'_id': ObjectId('641854c922eb732970d287cc'), 'name': '영희', 'age': 30} {'_id': ObjectId('641854e9a7a11c00924de5df'), 'name': '철수', 'age': 20} |
이와 같이 id 값이 붙어서 나오는 걸 볼 수 있다. 이 부분을 보지 않기 위해서 위와 같이 쓰는 것이다.
| {'name': 'bob', 'age': 27} {'name': '영희', 'age': 30} {'name': '철수', 'age': 20} |
반복문을 사용해 a를 찍어보면 이와 같이 저장된 데이터를 불러올 수 있다.
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
user = db.users.find_one({})
print(user)| {'_id': ObjectId('6418428374096d0a17110f66'), 'name': 'bob', 'age': 27} |
만약 하나만 가져오고 싶다고 하면 위와 같이 find_one 을 사용하면 된다.
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
db.users.update_one({'name':'bob'},{'$set':{'age':19}})db에 있는 데이터를 조작할 수 있다. update_one을 사용해 'name' : 'bob' 의 'age'를 19살로 바꾸라는 의미이다.

실행하고 새로고침을 하게되면 이와 같이 age가 바뀐걸 볼 수 있다
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
db.users.delete_one({'name':'bob'})delete_one은 조건 내에 있는 데이터를 삭제해준다. 저장 후 실행해보면 db에 해당 데이터가 사라져있는 것을 볼 수 있다.
pymongo 코드 요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})

영화 랭크, 제목, 평점을 웹크롤링해온 데이터를 db에 넣기위해 위 코드 5줄을 맨위에 붙여넣는다.
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a != None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text
doc = {
'title' : title,
'rank' : rank,
'star' : star
}
db.movies.insert_one(doc)변수 doc 에 넣고싶은 내용을 딕셔너리 형태로 할당을 해줬고 insert_one을 통해 db에 넣어줬다.

이와 같이 데이터가 db에 정상적으로 업로드 된 것을 볼 수 있다.
# 가버나움의 평점 가져오기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
movie = db.movies.find_one({'title':'가버나움'})
print(movie['star'])find_one({})을 통해 가버나움 데이터에 접근해서 movie['star']로 평점 데이터에만 접근했다.
# 가버나움과 평점이 같은 영화의 제목 가져오기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
movie = db.movies.find_one({'title':'가버나움'})
target_star = movie['star']
movies = list(db.movies.find({'star':target_star},{'_id':False}))find_one을 이용해 가버나움 데이터에 접근 후 변수 movie에 할당, 변수 target_star에 가버나움의 'star' 값을 할당
list(db.movies.find({},{}))를 통해 'star'의 값이 target_star 즉, 가버나움의 'star' 값과 같은 데이터들을 불러옴
| [{'title': '그린 북', 'rank': '02', 'star': '9.59'}, {'title': '가버나움', 'rank': '03', 'star': '9.59'}] |
이때 print(movies)를 하면 이와 같이 출력이 됨
for a in movies:
print(a['title'])반복문을 사용해서 a의 'title' 값만 출력함
# 가버나움의 평점을 0으로 만들기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb://sparta:test@ac-6joxava-shard-00-00.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-01.oag1hfc.mongodb.net:27017,ac-6joxava-shard-00-02.oag1hfc.mongodb.net:27017/?ssl=true&replicaSet=atlas-di6vv2-shard-0&authSource=admin&retryWrites=true&w=majority', tlsCAFile=ca)
db = client.dbsparta
db.movies.update_one({'title':'가버나움'},{'$set':{'star':0}})update_one 사용
# 지니 뮤직 사이트에서 음원 순위, 노래 제목, 가수 웹크롤링 해오기
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
name = tr.select_one('td.info > a.artist.ellipsis').text
print(rank,title,name)변수 trs에 <tr>태그의 공통부분을 할당한다.

<tr> 태그를 클릭하면 위와 같이 범위가 나온다.
반복문을 사용해 trs의 데이터를 tr에 순차적으로 넣어주면서 각 데이터에 맞는 부분을 넣어준다. 이때 글자부분만 가져오기 위해 text 메소드가 사용된 것이다.

rank를 print를 찍어보면 다음과 같이 나오기때문에 앞에 두글자만 출력하기 위해 [0:2]를 사용했고 공백을 없애기 위해 strip()를 사용했다.
| 1 바라만 본다 MSG워너비 (M.O.M) 2 Next Level aespa 3 신호등 이무진 4 Weekend 태연 (TAEYEON) 5 치맛바람 (Chi Mat Ba Ram) 브레이브걸스 (Brave girls) 6 Butter 방탄소년단 7 나를 아는 사람 MSG워너비 (정상동기) 8 Permission to Dance 방탄소년단 9 비 오는 날 듣기 좋은 노래 (Feat. Colde) 에픽하이 (EPIK HIGH) 10 헤픈 우연 헤이즈 (Heize) 11 하루만 더 빅마마 (Big Mama) 12 비와 당신 이무진 13 Alcohol-Free TWICE (트와이스) 14 롤린 (Rollin') 브레이브걸스 (Brave girls) 15 Peaches (Feat. Daniel Caesar & Giveon) Justin Bieber 16 Dun Dun Dance 오마이걸 (OH MY GIRL) 17 Dynamite 방탄소년단 18 라일락 아이유 (IU) 19 안녕 (Hello) 조이 (JOY) 20 추적이는 여름 비가 되어 장범준 21 운전만해 (We Ride) 브레이브걸스 (Brave girls) 22 Celebrity 아이유 (IU) 23 러브 (Prod. by 로코베리) 로꼬 & 이성경 24 Bad Habits Ed Sheeran 25 상상더하기 MSG워너비 26 ASAP STAYC (스테이씨) 27 상상더하기 라붐 (LABOUM) 28 밤이 되니까 원슈타인 29 Timeless SG워너비 30 좋아좋아 조정석 31 Savage Love (Laxed - Siren Beat) (BTS Remix) Jawsh 685 & Jason Derulo & 방탄소년단 32 다정히 내 이름을 부르면 경서예지 & 전건호 33 내 손을 잡아 아이유 (IU) 34 사이렌 Remix (Feat. UNEDUCATED KID & Paul Blanco) 호미들 35 At My Worst Pink Sweat$ 36 작은 것들을 위한 시 (Boy With Luv) (Feat. Halsey) 방탄소년단 37 OHAYO MY NIGHT 디핵 (D-Hack) & PATEKO 38 가을 우체국 앞에서 김대명 39 나는 너 좋아 장범준 40 멜로디 ASH ISLAND 41 Blueming 아이유 (IU) 42 밝게 빛나는 별이 되어 비춰줄게 송이한 43 에잇 (Prod. & Feat. SUGA of BTS) 아이유 (IU) 44 2002 Anne-Marie 45 LOVE DAY (2021) (바른연애 길잡이 X 양요섭, 정은지) 양요섭 & 정은지 46 아로하 조정석 47 흔들리는 꽃들 속에서 네 샴푸향이 느껴진거야 장범준 48 이제 나만 믿어요 임영웅 49 낙하 (With 아이유) AKMU (악뮤) 50 Off My Face Justin Bieber |
코드를 찍어보면 다음과 같은 결과물이 나오게 된다.
'코딩 > 웹개발 종합반' 카테고리의 다른 글
| 웹개발 종합반 4주차(스파르타 피디아) (0) | 2023.03.22 |
|---|---|
| 웹개발 종합반 4주차(화성땅 공동구매) (0) | 2023.03.21 |
| 웹개발 종합반 4주차 (0) | 2023.03.21 |
| 웹개발 종합반 2주차 (0) | 2023.03.13 |
| 웹개발 종합반 1주차 (0) | 2023.03.09 |




댓글